线性回归
例子:预测住房价格
数据集:已知一个数据集,包含某个城市的住房价格。每个样本包括房屋尺寸、售价。
问题:根据不同房屋尺寸所售出的价格,画出数据集。如果房子是1250平方尺,你要告诉他们这房子能卖多少钱。
首先,你可以构建一个模型(假设是条直线,如下图)。根据数据模型,你可以告诉你的朋友,他的房子大约值220000美元。
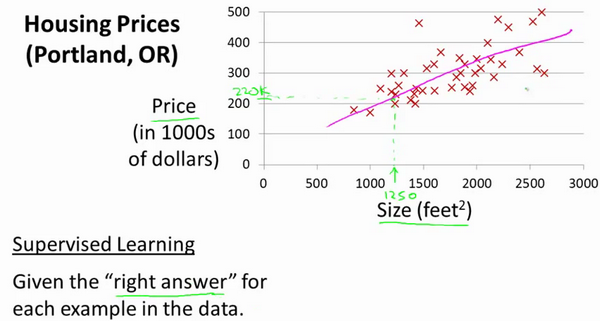
上述例子是个监督学习的例子,同时是一个回归问题。回归指根据之前的数据预测出一个准确的输出值,对于这个例子预测的值是价格。
这个数据集可以表示为下表:
| 房屋大小 (x) | 价格 (y) |
|---|---|
| 2104 | 460 |
| 1416 | 232 |
| 1534 | 315 |
| 852 | 178 |
| ... | ... |
我们用如下的符号来描述这个问题:
- m: 代表训练集中样本的数量(下文也将用 m 表示训练样本数量)
- x: 代表特征/输入变量
- y: 代表目标变量/输出变量
- (x, y): 代表训练集中的一个样本
- (x(i), y(i)):代表第 i 个观察样本
- h:代表学习算法的解决方案或函数也称为假设(hypothesis)
这个监督学习的工作方式如下:
训练集 → 学习算法
↓
房屋大小 → h → 预测价格
上述步骤总结为:
- 把训练集(房屋大小和价格)输入到学习算法;
- 学习算法计算出函数 h。函数输入是房屋大小 (x),输出 y 值对应房子的价格,因此 h 是一个从 x 到 y 的函数映射;
- 对于新要预测的样本 x,往 h 输入 x 值可得对应的 y 值。
那么,对于我们的房价预测问题, h 可能的表述如下:
,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
下一步是如何确定参数 θ0 和 θ1。在预测房价这个例子, θ1 是直线的斜率, θ0 是在 y 轴上的截距。
选择的参数决定了 h 相对与训练集的准确程度。
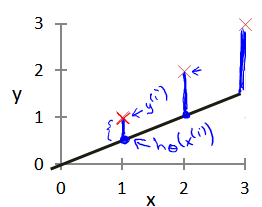
定义建模误差(modeling error)为模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)。
为衡量 h 的性能,回归任务中常见的方法是定义代价函数(Cost Function):
- 均方误差(MSE: Mean Squared Error)
- 选取参数以最小化 J,从而优化 h
我们绘制一个等高线图,三个坐标分别为 θ0 和 θ1、J(θ0, θ1),可以看到在三维空间中存在一个使得 J(θ0, θ1) 最小的点:
下右图是把代价函数呈现为等高线图(Contour Plot),以便我们观察 θ0 和 θ1 对 J(θ0, θ1) 的影响。
根据上图,人工的方法很容易找到 代价函数最小值时对应的 θ0 和 θ1,但我们真正需要的是一种有效的算法,能够自动地找出这些使代价函数 J 取最小值的参数 θ0 和 θ1。也就是下面要降到的梯度下降。
梯度下降是一种用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 J(θ0, θ1) 的最小值。
梯度下降的思想:开始时随机选择一个参数的组合 (θ0, θ1, ..., θn) ,计算代价函数;然后寻找下一个能让代价函数值下降最多的参数组合。持续这么做直到找到一个局部最小值(Local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(Global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
如下图所示,不同的起始参数导致了不同的局部最小值。
为了理解梯度下降,可以想象一下你正站立在山的一点上(上图中的红色起始点),并且希望用最短的时间下山。在梯度下降算法中,要做的就是旋转360度,看看周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,看一下周围,你会发现最佳的下山方向,按照自己的判断迈出一步;重复上面的步骤,从新的位置,环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
批量梯度下降(batch gradient descent)算法可以抽象为公式:
其中 α 是学习率(Learning rate),它决定了沿着能让代价函数下降程度最大的方向向下迈出的步子有多大;在批量梯度下降中,每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
上面的公式展开如下:
重点:更新上述式子需要同时更新一组参数 (θ0, θ1, ..., θn) ,之后再开始下一轮迭代。 这里先不解释为什么需要同时更新。但请记住,同时更新是梯度下降中常用方法。之后会讲到,同步更新也是更自然的实现方法。人们谈到梯度下降时,意思就是同步更新。
考虑上图中关于梯度下降的公式,其中求导,是取红点的切线,就是下图中红色的直线,其与函数相切于红色的点。红色直线的斜率,正好是下图红色三角形的高度除以这个水平长度,这条线有一个正斜率,也就是说它有正导数,因此,为了得到更新的 J,θ1 更新后等于 θ1 减去一个正数乘以 α。
α 的取值有怎么的影响?
- 如果 α 太小,即学习速率太小,结果是红点一点点挪动,努力去接近最低点,需要很多步才能到达最低点。同样会需要很多步才能到达全局最低点。(如下图-左图)
- 如果 α 太大,梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,一次次越过最低点,直到你发现实际上离最低点越来越远,所以如果 α 太大,它会导致无法收敛,甚至发散。(如下图-右图)

现在,还有一个问题,需要思考,如果我们预先把 θ1 放在一个局部的最低点,下一步梯度下降法会怎样工作?
假设你将 θ1 初始化在局部最低点,它已经在一个局部的最优处或局部最低点。结果是局部最优点的导数将等于零,因为它是那条切线的斜率。使得 θ1 不再改变,也就是新的 θ1 等于原来的 θ1 ,因此,如果参数已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率 α 保持不变时,梯度下降也可以收敛到局部最低点。
我们再来看下代价函数 J(θ) ,如下图
随着接近最低点,导数越来越接近零,所以,梯度下降一步后,新的导数会变小一点点。再梯度下降一步,在这个绿点,会用一个稍微跟刚才在那个品红点时比,再小一点的一步,到了新的红色点,更接近全局最低点了,因此这点的导数会比在绿点时更小。所以,再进行一步梯度下降时,导数项是更小的, θ1 更新的幅度就会更小。所以随着梯度下降法的运行,移动的幅度会自动变得越来越小,直到最终移动幅度非常小,这时已经收敛到局部极小值。
总结一下:
- 在梯度下降法中,当接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当接近局部最低点时,导数值会自动变得越来越小,梯度下降将自动采取较小的幅度。所以实际上没有必要再另外减小 α。
- 你可以用它来最小化任何代价函数 J(θ) ,不只是线性回归中的代价函数 J(θ)。
这一节介绍如何将梯度下降和代价函数结合。
梯度下降算法和线性回归算法比较如图:
回顾一下之前的线性回归问题的代价函数:
其偏导数为:
- 当 j = 0 时:
- 当 j = 1 时:
所以算法可以写为:
Repeat {
}
上述算法有时也称为 批量梯度下降(Batch Gradient Descent)。“批量”是指在梯度下降的每一步中,我们都用到了所有的训练样本。
- 在梯度下降,计算微分求导项时,需要求和运算,所以,在每一个单独的梯度下降中,最终都要计算这样一个东西,这个项需要对所有 m 个训练样本求和。
- 批量梯度下降法这个名字说明需要考虑所有这一"批"训练样本。事实上,也有其他类型的梯度下降法,不是"批量"型的,不考虑整个的训练集,每次只关注训练集中的一些小的子集。后续会介绍。
此外,也许你知道有一种计算代价函数最小值的数值解法,不需要梯度下降这种迭代算法。在后面我们也会谈到这个方法,可以在不需要多步梯度下降的情况下,解出代价函数的最小值,这中方法称为正规方程(normal equations)。实际上在数据量较大的情况下,梯度下降法比正规方程要更适用一些。
在之前的房价预测问题里,只考虑到房屋尺寸一个特征,这里我们考虑多个特征的问题。比如在房价预测问题中,引入房间数、楼层、年限等。
下表是一个示例数据:
| 房屋大小 | 房间数 | 楼层 | 年限 | 价格 (y) |
|---|---|---|---|---|
| 2104 | 5 | 1 | 45 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| 1534 | 3 | 2 | 30 | 315 |
| 852 | 2 | 1 | 36 | 178 |
| ... | ... | ... | ... | ... |
介绍更多的问题描述符号:
- n:特征的数量
- x(i):第i个训练样本。如果样本用矩阵表示,那它对应就是矩阵的第 i 行,也是一个向量。比如 x(2) = [1416; 3; 2; 40; 232]。
- xj(i):训练样本中的第 i 个hang本中的第 j 个特征,也就是矩阵里的 i 行的 j 列。
多变量的假设 ℎ 表示为:
上述公式中有 n+1 个参数和 n 个变量,为了简化公式,引入 x0 = 1,则上式写作:
其中,T 代表矩阵转置
在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:
计算代价函数的Python代码如下:
def compute_cost(X, y, theta): inner = np.power(((X * theta.T) - y), 2) return np.sum(inner) / (2 * len(X))
多变量梯度下降的目标和单变量线性回归问题中一样,要找出使得代价函数最小的一系列参数。多变量线性回归的批量梯度下降算法为:
求导后得到:
可以看出,有 n 个特诊的梯度下降算法和算法 单特征的梯度下降算法的区别是 θ 变量的个数及在每一步更新 θ 变量的个数。
在面对多维特征问题时,要保证这些特征都具有相近的尺度,将使梯度下降算法更快地收敛。
以房价问题为例,假如有两个特征,房屋尺寸和房间数量。尺寸值为 0-2000平方英尺,房间数量取值0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。如下图:
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图右图:
对于X数据的标准化公式:
其中 μn 是平均值,sn 是标准差。Python示例代码如下:
import numpy as np X = np.random.rand(5, 2)mu = np.mean(X, axis=0)
std = np.std(X, axis=0)
X = X - mu
X = X / std
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,虽不能提前预知,但可以画出迭代次数和代价函数 J 的图表来观测算法在何时趋于收敛。如下图所示,可以看到 J 是随着迭代次数增加而不断的减小。当迭代次数达到300之后, J 降低的趋势已经非常小了,说明已经收敛。
也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如0.001)进行比较,如果比阈值小,就认为已经收敛。但通常看上面这样的图表更好。
梯度下降算法的迭代受到学习率 α 影响:
- 如果学习率 α 过小,则达到收敛所需的迭代次数会非常高;
- 如果学习率 α 过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试些学习率: α = 0.01,0.03,0.1,0.3,1,3,10
最后,大的原则是,有效的 α 是可以让 J 随着迭代不断变小。但太小的 α 会导致收敛的很慢。
仍然是以房价预测为例:
按照此前的线性回归模型可得: hθ(x) = θ0 + θ1 × frontage + θ2 × depth
定义:
- x1 = frontage(临街宽度)
- x2 = depth(纵向深度)
- x = frontage*depth = area(面积)
则:hθ(x) = θ0 + θ1x。
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型:hθ(x) = θ0 + θ1x1 + θ2x2 或者三次方模型: hθ(x) = θ0 + θ1x1 + θ2x2 + θ3x3。如下图所示:
通常我们需要先观察数据然后再决定模型的类型。此外,可以令 x2 = x2,x3 = x3,从而将多项式回归转换为线性回归。
我们都在使用梯度下降算法,但是对于某些线性回归问题,正规方程方法是更好的解决方案。如:
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:。 假设我们的训练集特征矩阵为 X(包含了 x0 = 1)并且我们的训练集结果为向量 y,则利用正规方程解出向量:
θ = (XTX)-1XTy
推导如下:
举个例子:
运用正规方程方法求解参数:
上面的正规方程用Python的实现如下:
import numpy as npdef normal_equation(X, y):
theta = np.linalg.pinv(X.T @ X) @ X.T @ y
注意:对于不可逆的矩阵 X(通常因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用。
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 α | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量 n 很大时也适用 | 需要计算 (XTX)-1 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为 O(n3),通常来说当 n 小于10000 时还是可以接受 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
我们称那些不可逆矩阵为奇异或退化矩阵。有两种情况可能导致矩阵的不可逆:
- 在 m 小于或等于 n
- 我们会使用一种叫做正则化(Regularization)的线性代数方法删除某些特征
- 特征之间线性相关:
- 可以删除这两个重复特征里的其中一个
- 推荐访问Google Drive的共享,直接在Google Colab在线运行ipynb文件:
- 不能翻墙的朋友,可以访问GitHub下载: